Over-Provisioned Resources Use Case
In this use case, we search for resources which hardware utilization does not justify their SKU size.
Resources that are identified by this use case, can arise simply by wrong capacity planning, scaled up resource which was not scaled down after the demand has disappeared and more scenarios.
Actions to take against identified resources
The default action to take against these resources is resize. If you are unsure or require greater confirmation, you can wait some time and if the resource is still showing up as over-provisioned take action after.
For some resources, it is impossible to classify them as unused, because they emit at least minimal usage. It is possible that this use case will help you to identify unused resource - example scenario:
- Virtual machine with 32 GBs of RAM and 8 CPUs is marked as over-provisioned
- You perform resize to 16 GBs of RAM and 4 CPUs, resource shows as over-provisioned next month again
- You perform resize to 8 GBs of RAM and 2 CPUs, resource shows as over-provisioned next month again
- At this point you can resize to smallest possible size or consider of having look into the VM, because this suggests that there is nothing happening that would require hardware utilization
Rationale behind searching for over-provisioned resources
When searching for over-provisioned resource we use this assumption: If there is no legitimate reason for the resource to stay in its current SKU size, identify it as over-provisioned. This translates to following examples:
- For premium SSD disk, we search if standard SSD disk would be viable option respecting the standard disk performance targets
- For App Service Plan with 8 GBs RAM and 4 CPUs, we try to fit current usage to 4 GBs RAM and 2 CPUs
- For Database with 100 DTUs we measure if cutting down usage by 50% (e.g. scaling it to 50 DTUs) would still meet the historical usage
The general rule of thumb is that if resource shows as Over-Provisioned, you can assume re-size to 50% of its current size. There are exceptions such as disks, because there is nothing between premium and standard disk.
False positives
We estimate that this use case will have 75% - 90% confidence. Initial confidence of 75% will grow the longer the resource is identified.
Detection of over-provisioned resources is smart to detect spikes in usages and resources emitting this behavior will not be identified. Example of spikes in usage:
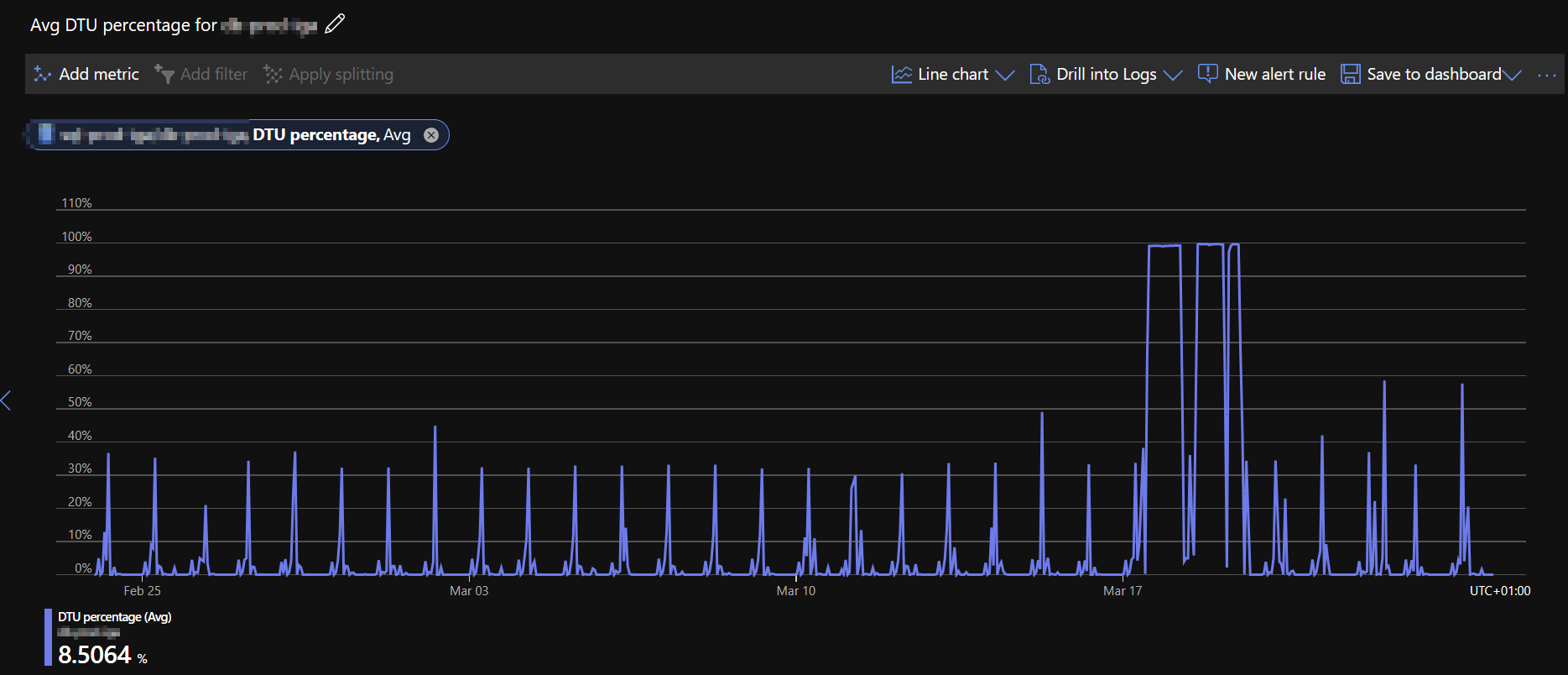
Spikes can be predictable loads, scheduled jobs etc., resizing such resources would most likely cause hardware starvation and issues at runtime such as timeouts, out of memory errors, ...